
投資するなら長期…なので過去の財務状態も長期で分析したい
どーもどーも.
日々節約したおカネを投資に回して,「日々の株の上げ下げではなく配当というリターン」をコツコツ積みたい管理人です.
さて,そうなると数年…数十年単位で積み立て投資をする可能性が高くなるわけで,倹しく節約したおカネを投じる会社が「どんな事業をしているか」「30年後,爆上りはせずとも存在していると言えそうか」が大事になると思うのです.
そして,そんな長期スパンで資金を投じる会社は,長期間の過去にはどんな業績だったか…気になるよね?気になります.
気になる会社の有価証券報告書をひたすら取り寄せて数字をスプレッドシートに打ち込むのも嫌いじゃあないけど,
世の中,有価証券報告書のXBRLファイルというものが金融庁のEDINETから開示されていて,それを読み解くとかなり深いところまで解析ができる.
しかしこれが5年分しか開示されないので,これまたコツコツダウンロードして手元に置いてもっと長期軸で分析しようかなー,と思うのだ.
で…久しぶりにEDINETを除いたら「一括ダウンロード」が出来なくなっていたorz
なんてぇこった…
というわけで,最近触ることが増えたpythonで,欲しい期間のXBRLファイル(全銘柄分)を自動でダウンロードできないか??調べてみた.
EDINET APIを使ってダウンロード
残念ながら管理人にはpythonで自在にコードを作る能力はないので(物理現象を数式に下すことはできるけどさ),ググって先人の知恵を拝借して改造する.こちらのページとこちらのページがすっごく参考になりました…
それぞれの関数で何をしているかはコメントアウトに書いてみた.コードの書き方が素人全開なのはご愛敬.
やりたいこととしてはXBRLファイルからデータを抜き出して会計年度ごとに財務&経営状態の変化を見ること…なので,「任意の期間に提出された有価証券報告書(XBRL)を一括でZIP形式でダウンロード」「ZIPは書類提出年ごとに,ZIPを解凍したファイルは会計期間の開始年ごとに整理」するように改造してみた.それ以外はほぼ先人の知恵の通りのコードだ.
"""--------------------プログラムの更新履歴--------------------"""
#■更新履歴
# 230129 ver1. xbrlデータ四半期レポートのダウンロードコード,こちらを参考.https://qlitre-weblog.com/how-to-get-financial-infomation-using-python/
# 230129 ver2.有価証券報告書の一括ダウンロード用に改造.https://qiita.com/XBRLJapan/items/27e623b8ca871740f352
# 230129 ver2_2.【仕様変更】zipの保存先は文書開示年ごとに整理し,解凍したデータは決算対象期間の開始年ごとに整理する
# 上記必要な改造は…①解凍する,②決算年→EdinetCodeごとのフォルダに解凍後のデータを入れる.解凍前のデータは年ごとにまとめる
#
# ■ローカルルール
# データフレームは***_DF,データリストは***_DL,
# 一次元配列(横方向に数値が並ぶヤツ)は***_Ar
# 「二次元配列=行列」でX方向にデータを持つのは***_X,Y方向にデータを持つのは***_Y
# 「二次元配列=行列}でXY両方向にデータを持つのは***_XYと記述する
"""--------------------プログラムの更新履歴,以上--------------------"""
# -*- coding: utf-8 -*-
import zipfile
import os
from pathlib import Path
import requests
import datetime
"""--------------------以下,サブ関数--------------------"""
def Make_InputDate_DL(InputDateSta, InputDateEnd):
print("InputDateSta=", InputDateSta,"InputDateEnd=", InputDateEnd)
Period = InputDateEnd - InputDateSta
Period = int(Period.days)
InputDate_DL = []
for d in range(Period):
day = InputDateSta + datetime.timedelta(days=d)
InputDate_DL.append(day)
InputDate_DL.append(InputDateEnd)
return (InputDate_DL)
#230129. データリスト作成.ドキュメント取得に必要なDocIDの他に,ファイル仕分けに使うEdinetoCodeなども出力しておく.
def MakeDataList_ver1(InputDate_DL,FormCode):
DocID_DL = []
EdinetCode_DL = []
PeriodSta_DL = []
PeriodEnd_DL=[]
SubmitDate_DL=[]
for index, day in enumerate(InputDate_DL):
url = "https://disclosure.edinet-fsa.go.jp/api/v1/documents.json"
params = {"date": day, "type": 2}
proxies = {
"http_proxy": "http://username:password@proxy.example.com:8080",
"https_proxy": "https://username:password@proxy.example.com:8080"
}
res = requests.get(url, params=params, proxies=proxies)
json_data = res.json()
print(day)
for num in range(len(json_data["results"])):
ordinance_code = json_data["results"][num]["ordinanceCode"]
form_code = json_data["results"][num]["formCode"]
if ordinance_code == "010" and form_code == FormCode:#FormCodeに応じて,ダウンロードする書類を変えられる
print(json_data["results"][num]["filerName"], json_data["results"][num]["docDescription"],
json_data["results"][num]["docID"])
DocID_DL.append(json_data["results"][num]["docID"])#docIDのデータリストを作成
EdinetCode_DL.append(json_data["results"][num]["edinetCode"])#EdinetCodeのデータリストを作成
PeriodSta_DL.append(json_data["results"][num]["periodStart"]) # periodStartのデータリストを作成
PeriodEnd_DL.append(json_data["results"][num]["periodEnd"]) # periodEndのデータリストを作成
SubmitDate_DL.append(json_data["results"][num]["submitDateTime"]) #書類提出日時のデータリストを作成
#print('json_data["results"]=', json_data["results"])
print('EdinetCode_DL=',EdinetCode_DL)
return (DocID_DL,EdinetCode_DL,PeriodSta_DL,PeriodEnd_DL,SubmitDate_DL)
# 230129. xbrlをzipでダウンロードし,zipは文書開示年ごとに,解凍したファイルは決算対象期間の開始年ごとに整理
def SubCal_DownloadXbrl_ver1(BasePath,DocID_DL, EdinetCode_DL,PeriodSta_DL,PeriodEnd_DL,SubmitDate_DL):
NumData=len(DocID_DL)
for index, DocID in enumerate(DocID_DL):
EdinetCode=EdinetCode_DL[index]
PeriodSta = PeriodSta_DL[index]
PeriodEnd=PeriodEnd_DL[index]
SubmitDate = SubmitDate_DL[index]
print(DocID, ":", index + 1, "/", NumData)
print('EdinetCode=', EdinetCode,'PeriodSta=', PeriodSta,'PeriodEnd=', PeriodEnd,'SubmitDate=', SubmitDate)
if FormCode=="030000":
YYYY_UnZipped=PeriodSta[0:4]#会計期間開始年を西暦(文字列)で取得
YYYY_Zip = SubmitDate[0:4]#書類提出年を西暦(文字列)で取得
else:
YYYY_UnZipped = SubmitDate[0:4] # 書類提出年を西暦(文字列)で取得
YYYY_Zip = SubmitDate[0:4] # 書類提出年を西暦(文字列)で取得
url = "https://disclosure.edinet-fsa.go.jp/api/v1/documents/" + DocID
params = {"type": 1}
#zipファイルの保存先を作る
ZipPath=BasePath+"Zip//"+YYYY_Zip#zipファイルは,書類提出年でフォルダ分けする
if not os.path.exists(Path(ZipPath)):#保存先のフォルダが存在しないなら作る
os.makedirs(Path(ZipPath))
FileName = ZipPath+ "//" + EdinetCode+"_"+DocID
FileName_zip = FileName + ".zip"
#解凍するファイルの展開先を指示
UnZippedPath=BasePath +"UnZipped//"+ YYYY_UnZipped+ "//"+ EdinetCode+"_"+DocID#解凍したファイルは会計期間開始年でフォルダ分けする
res = requests.get(url, params=params, stream=True)
if res.status_code == 200:
# zipファイルを作成する
with open(FileName_zip, 'wb') as file:
for chunk in res.iter_content(chunk_size=1024):
file.write(chunk)
# zipファイルを解凍する
with zipfile.ZipFile(FileName_zip) as existing_zip:
#existing_zip.extractall(FileName)
existing_zip.extractall(UnZippedPath)
existing_zip.close()#←zipをクローズする
"""----------------------------------以下,メイン関数----------------------------------"""
"""ドキュメントを収集したい期間を設定する"""
InputDateSta = datetime.date(2019, 6, 1)#収集開始日
InputDateEnd = datetime.date(2019, 6, 30)#収集終了日
InputDate_DL = Make_InputDate_DL(InputDateSta, InputDateEnd)
print(InputDate_DL)
"""設定した期間に応じて,ドキュメントIDその他を取得する"""
FormCode="030000"#〇有価証券報告書
#FormCode="030001"#〇訂正有価証券報告書
#FormCode="043000"#〇四半期報告書
#FormCode="043001"#〇訂正四半期報告書
(DocID_DL,EdinetCode_DL,PeriodSta_DL,PeriodEnd_DL,SubmitDate_DL)= MakeDataList_ver1(InputDate_DL,FormCode)
print("NumData=", len(DocID_DL))
print("DocID_DL=", DocID_DL)
print("EdinetCode_DL=", EdinetCode_DL)
print("PeriodSta_DL=", PeriodSta_DL)
print("PeriodEnd_DL=", PeriodEnd_DL)
"""保存先のパスを設定して,xbrlファイルその他を保存する"""
if FormCode=="030000":
BasePath = "D://XBRL//00_SecReport//"
elif FormCode=="030001":
BasePath = "D://XBRL//01_AmendedSecReport//"
elif FormCode=="043000":
BasePath = "D://XBRL//02_QuarterlySecReport//"
elif FormCode=="043001":
BasePath = "D://XBRL//03_AmendedQuarterlySecReport//"
else:
print('正しいFormCodeを入力してね(^o^)ノシ')
breakpoint()
SubCal_DownloadXbrl_ver1(BasePath,DocID_DL, EdinetCode_DL,PeriodSta_DL,PeriodEnd_DL,SubmitDate_DL)
print("Download Fin. (^o^)ノシ")
実際にダウンロードしてみる
ダウンロード先のフォルダ構成はこんな感じにセットしてある.
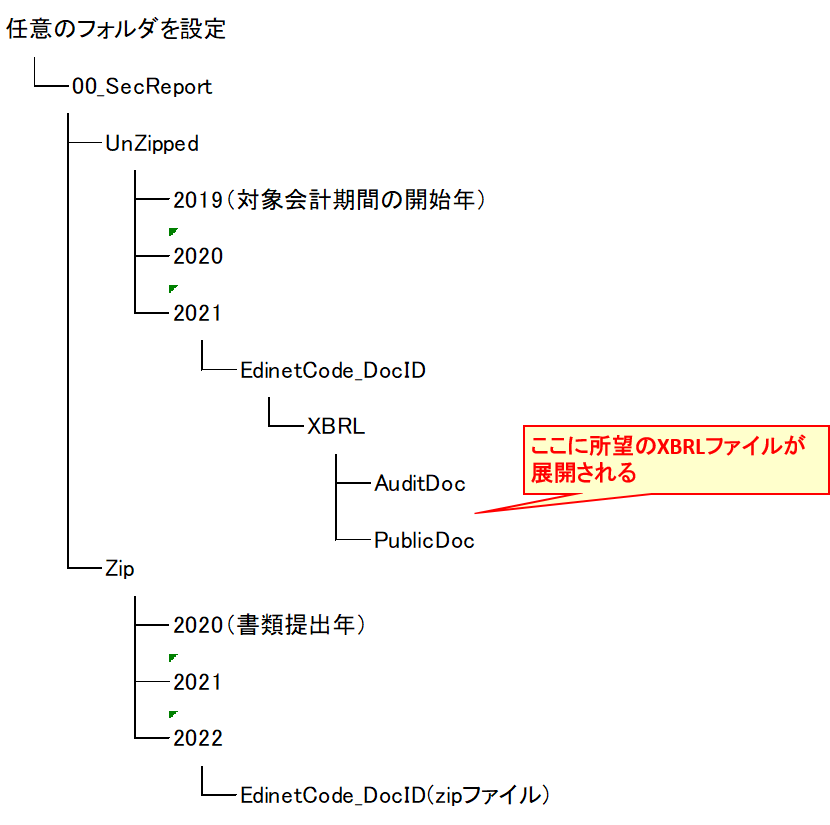
で,書類提出日の範囲を設定して,コードを実行するとこんな感じでゆっくりとダウンロードしてくれる.1件1~3秒くらいかな?結構かかる.
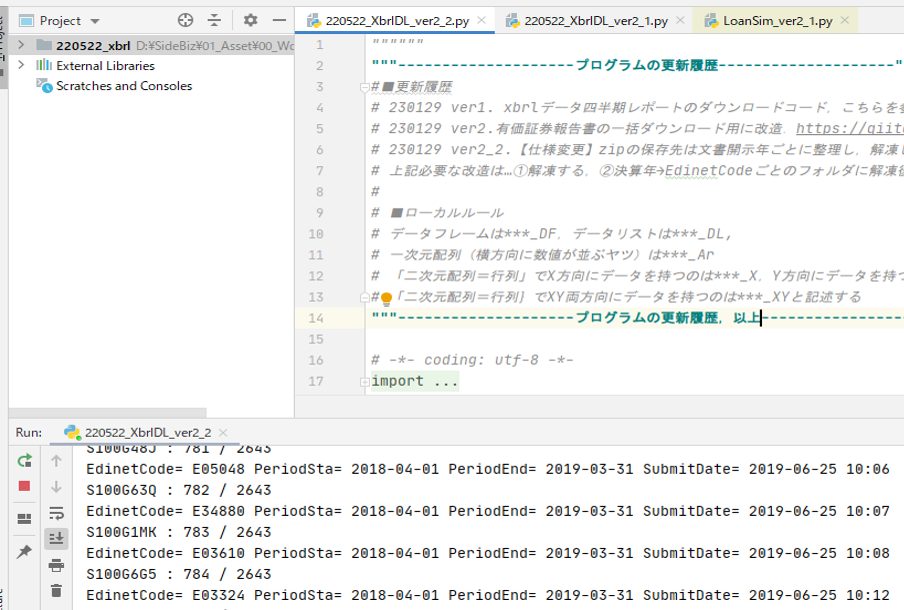
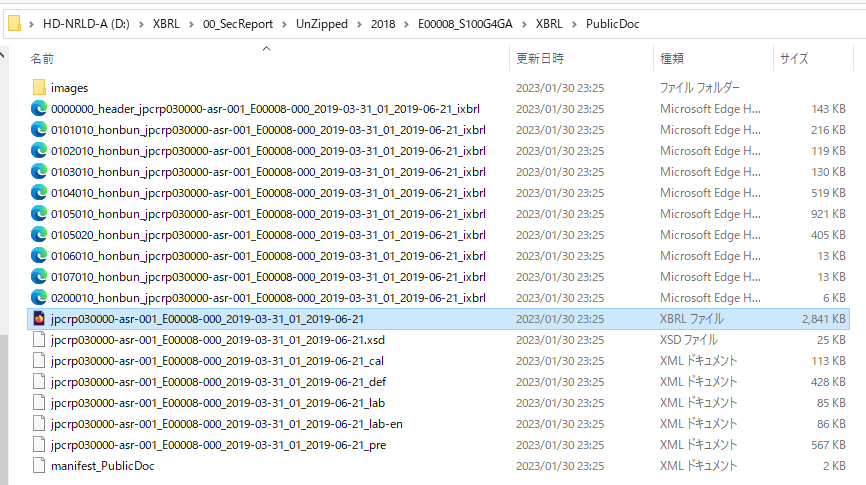
最終的にはこんな感じでデータが格納される.良き良き!が書類提出日の範囲を長く設定して放置しようとしたら,結構エラーで止まる.提出日の範囲は1か月くらいが良いみたい(理由はわからない).とりあえずダウンロードする手段は確保できた.
結論
pythonを使って,有価証券報告書のXBRLファイルを自動でダウンロードできないか調べ,
「EDINET APIを使ってコードを作ることで,無事ダウンロードできた」「数年分ひとまとめで…とはいかなかったが1か月分ずつダウンロードするにしても,EDINETのページから手動で落とすより,はるかに楽だった」
との結果を得た.これで分析用のデータ「だけ」大量に手元に置くことができた.が,その前に,ちゃんと投資先の会社の有価証券報告書を読まないとな…

コメント